MetaのAI研究部門「FAIR(Fundamental AI Research)」は、音声とテキストの統合に特化した新たな大規模言語モデル「Meta Spirit LM」を公開しました。音声認識から音声生成まで生成過程を一本化し、話者の抑揚や感情を反映した音声出力が可能になるとしています。

テキストだけでは表現しきれない音声のニュアンスを認識可能に
「Meta Spirit LM」は、従来の音声認識やテキスト生成の手法に代わり、テキストと音声の相互変換を自然な表現で行うモデルとして開発されました。
本モデルの特徴は、音声における抑揚や感情を反映できる点にあります。特に「Spirit LM Expressive」バージョンでは、ピッチやスタイルについてのトークンを用いることで、ユーザーの感情に応じた生成が可能です。FAIRは、テキストだけでは表現しきれない、音声ならではのニュアンスを取り入れることができます。
MetaのAI開発は続く
Metaは本リリースを通じて、テキストと音声の垣根を取り払い、マルチモーダルな生成を目指す研究コミュニティの発展を支援するとしています。
この技術の公開により、音声合成や自動音声認識といった用途を含むさまざまな領域での応用が期待されています。FAIRは、他の研究機関や開発者と連携しながら、AIを用いた新たな表現や、AIと人間の円滑な協働の実現に向けた取り組みを今後も進めていく方針です。
FAIRとは
Metaの「FAIR(Fundamental AI Research)」は、先進的な機械知能(AMI)の実現を目指し、オープンサイエンスと再現性を支援するために活動しています。FAIRは、AIコミュニティと連携しながら、機械学習や自然言語処理、画像解析などの分野で最先端の研究を進めています。過去10年以上にわたり、FAIRは新しい研究成果やモデル、データセットを公開し、AIの発展と社会的利益を追求しています。
参照元:Sharing new research, models, and datasets from Meta FAIR

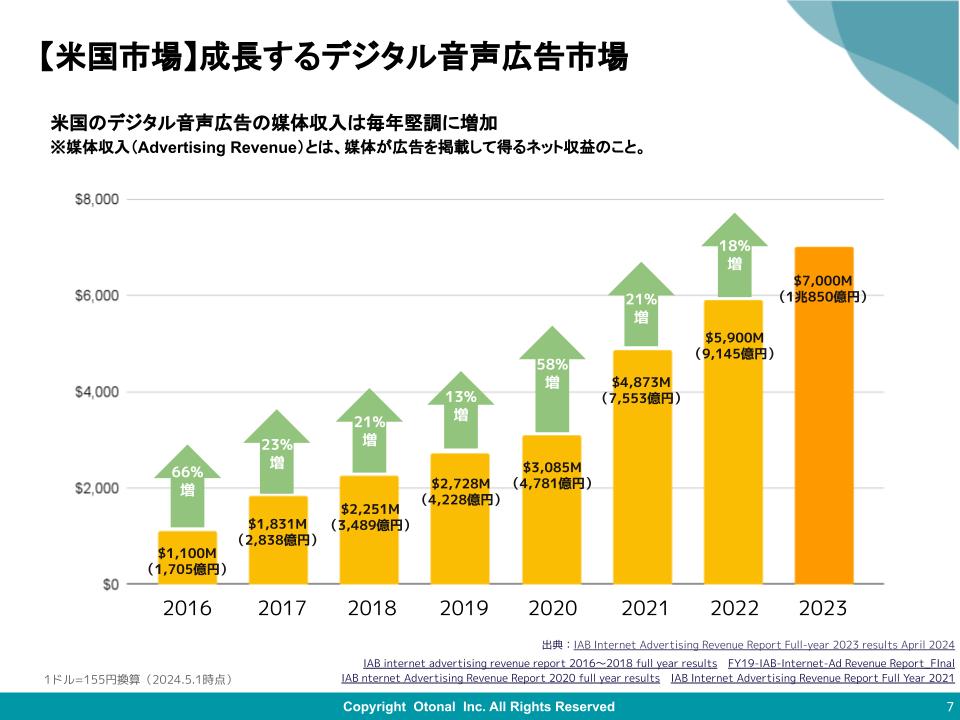
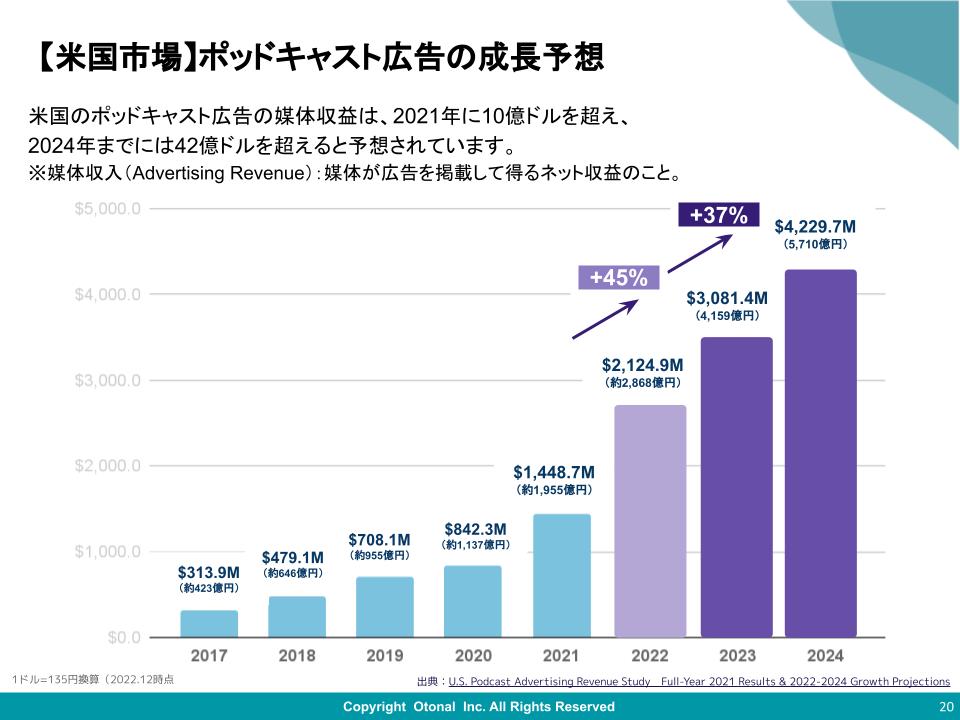




横文字が続くけど、これもAIに翻訳してもらわなくちゃね。