Amazonが音声言語モデル「BASE TTS」を発表しました。AIを用いたテキスト読み上げ技術(TTS:Text-to-Speech)であるBASE TTSを音声アシスタントに採用すると、従来よりも自然で人間のようなコミュニケーションが可能になるとのことです。

引用元:amazon.science
BASE TTSは、公開ドメインから収集された10万時間以上の音声データを学習材料にしており、約10億のパラメーターを有しています。
BASE TTSは従来のTTSモデルを遥かに超える自然な話し声を実現し、テキストの理解に基づいて感情や抑揚を声に反映させることが可能です。大量の音声データによって学習したため、BASE TTSは「emergent abilities(創発的能力、本来の目的とは異なる文章生成能力や問題解決能力のこと)」の発揮が見込めるとされています。
様々な分野での応用に期待
BASE TTSは、オーディオブックの読み上げ、自動翻訳、アシスタント技術など、様々な分野での応用が期待されています。今後BASE TTSがどのように活用されていくのか注目されていくでしょう。
TTSとは
TTS(Text-to-Speech)は、テキスト情報を音声情報に変換する技術です。TTSにより、コンピュータが人間の言葉を模倣して読み上げることが可能になります。視覚障害者の読書支援、ナビゲーションシステム、自動音声応答システムなど、様々な分野で利用されています。AIと機械学習の進歩により、TTSはより自然で理解しやすい音声を生成できるようになっています。
参照元:BASE TTS: Lessons from building a billion-parameter text-to-speech model on 100K hours of data

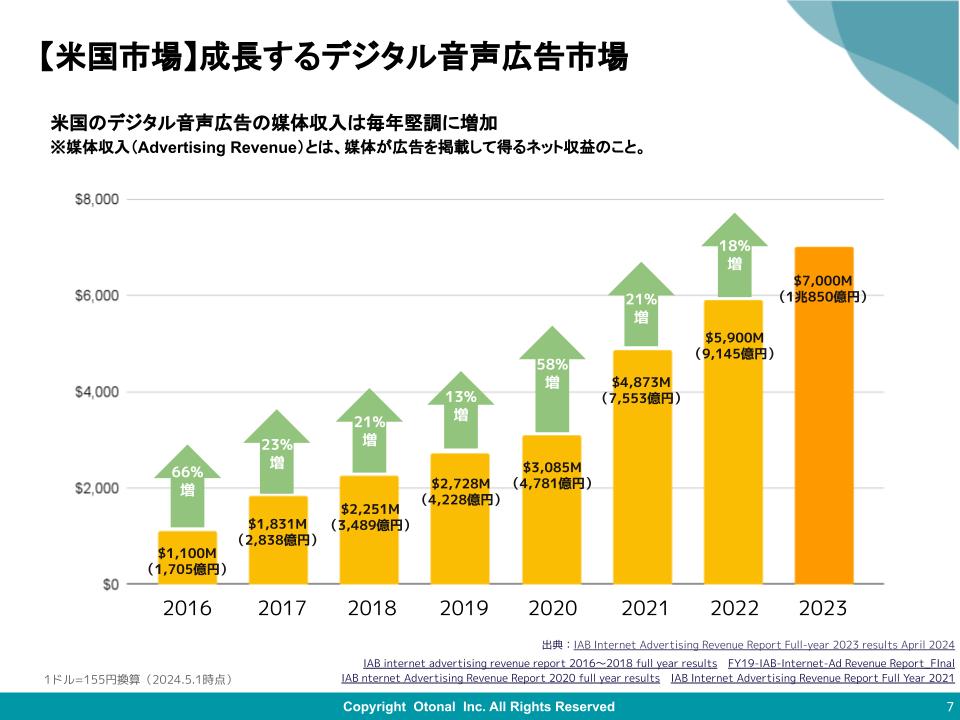
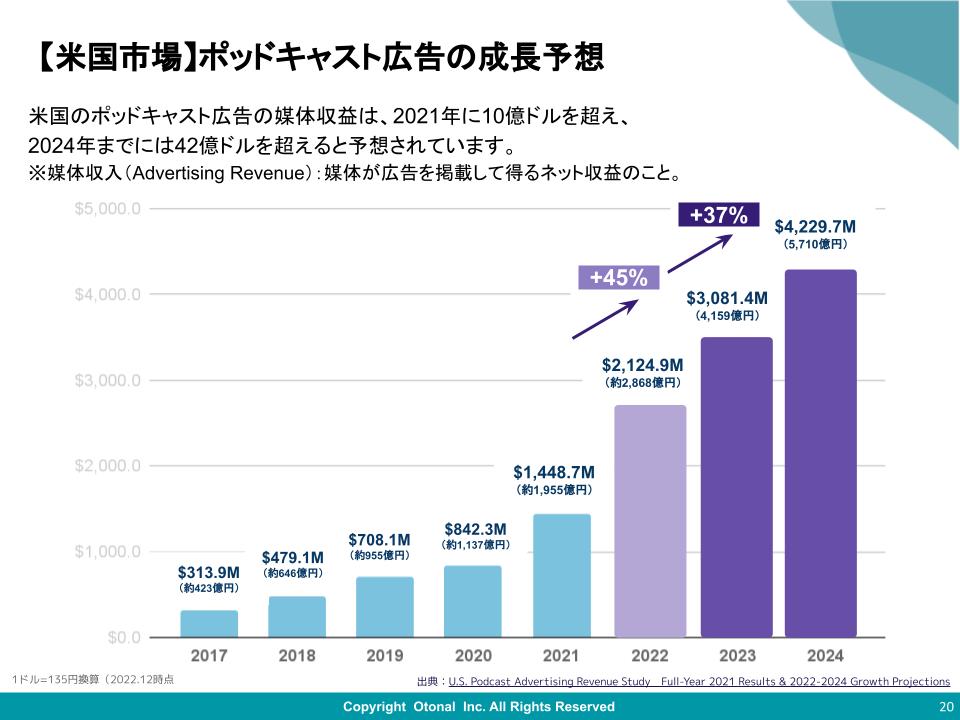




日本語でどれくらいの性能が出るのか気になるね。