独自のAI開発などを行っているGoogleのAI部門DeepMindが、AIによって生成された映像用に、AI音声を生成する技術を新たに発表しました。
これまでの技術では、生成AIによる映像に音声を付けることができませんでした。今回、DeepMindが発表した新技術では、映像に対してAI音声を生成することが可能になります。

引用元:deepmind.google
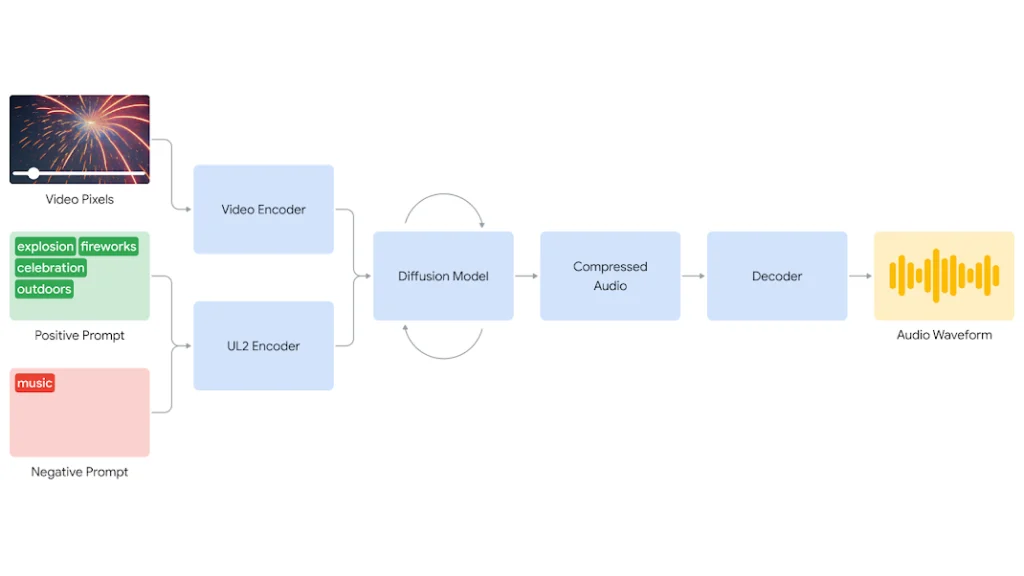
DeepMindのV2A技術とは
DeepMindが今回発表した映像にAI音声を付ける技術(V2A)は、入力された映像(音声を付けたい映像)と、プロンプト(AIに対する指示)を組み合わせたものとなっています。例えば、ドラムをたたいている映像をAIで出力して、音声を付けたい場合は、その映像と音のイメージに合うプロンプトを入力することで音声を生成できます。実際にGoogle DeepMindが公開したデモ映像を見てみましょう。
引用元:deepmind.google
V2A技術の特徴
DeepMindのV2A技術の特徴は大きく二つあるといえるでしょう。
一つは先ほども解説したように、音声の生成をプロンプトによってだけではなく、映像の解析も含めて行っている点です。これにより、より映像にマッチした音声の生成が可能となっています。
もう一つは、あるゆるタイプの映像の入力に対応しているということです。このV2A技術はGoogleがこれまで開発してきたAI映像生成技術(Veo)によって生成映像だけでなく、実際に撮影された映像への音声生成にも対応しています。これによってこのV2A技術の用途は大幅に拡張されたといえるでしょう。
下の動画は、実際に撮影された映像にAIによって音声を付けている例です。
V2A技術の問題点
革新的な技術のように思えるDeepMindのV2A技術ですが、未だ問題を抱えているとのいいます。問題の一つが、生成する音声の品質が映像の品質に依存していることです。また、しゃべっている映像に、音声変換したテキストをあてがう「リップシンク」も、まだ改善の余地があるとしています。
Google DeepMindとは
Google DeepMindは、2010年に設立されたイギリスのAI研究企業で、2014年にGoogleに買収されました。DeepMindは主に人工知能の研究に注力しており、特に強化学習やディープラーニングを用いた技術が有名です。同社の開発したAI「AlphaGo」は、囲碁の世界チャンピオンを破るなど、AI技術の高さを世界に示しました。また、DeepMindはAIの安全性に関する国際的な協力を促進するための取り組みを続けており、安全なAI開発のフレームワークを導入しています。
参照元:Generating audio for video

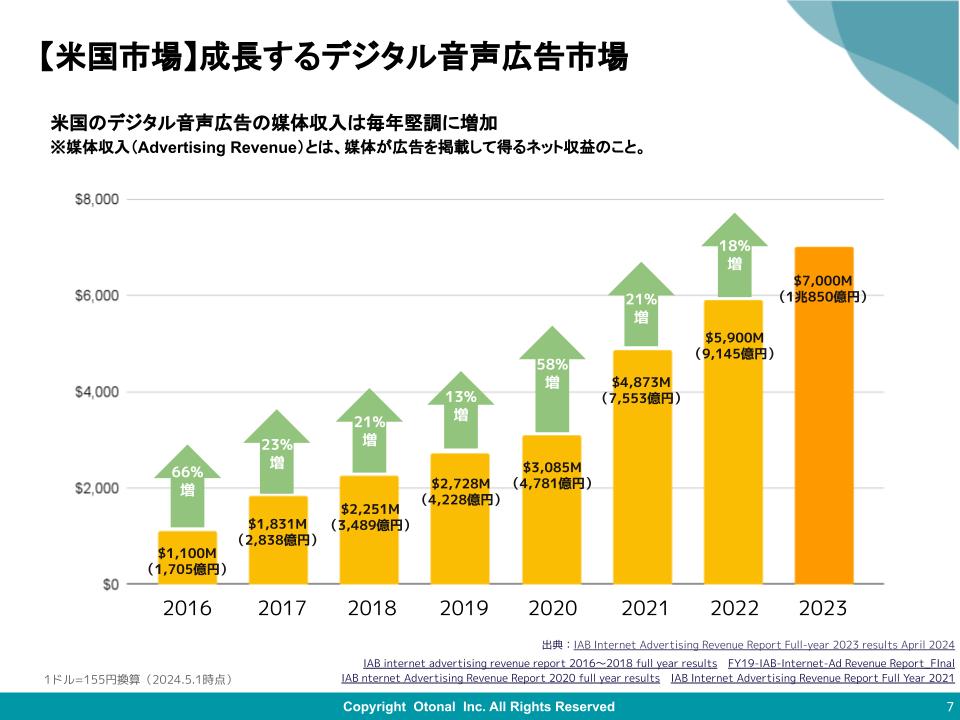
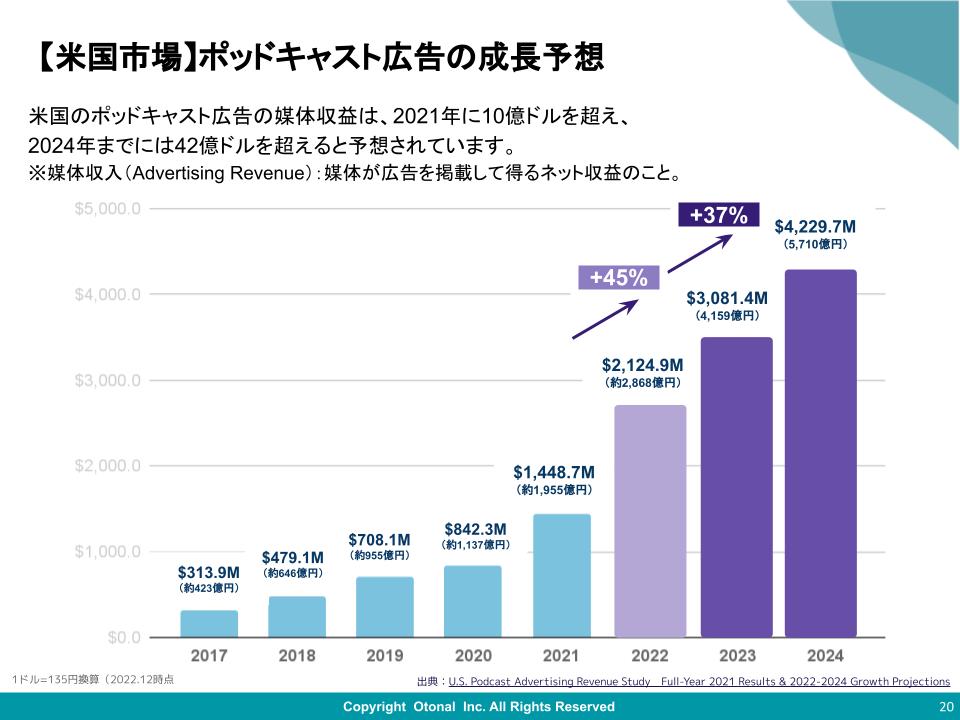


![[科学で考えるソニックマーケティング]第4回:ちょっぴり残念なお知らせ・・・万能の店舗BGMはありません](https://otonal.co.jp/wp-content/uploads/2024/05/2024-05-24-16-50.png)


AIだけで、映画とかCMを作れるようになる日は近い...?。映像というものがコモディティ化しそう。