FacebookやInstagramを提供するmeta(メタ)が次世代音声AIモデル「Audiobox」を発表しました。このAIモデルは音声や効果音など、幅広い音声を生成可能とのことです。
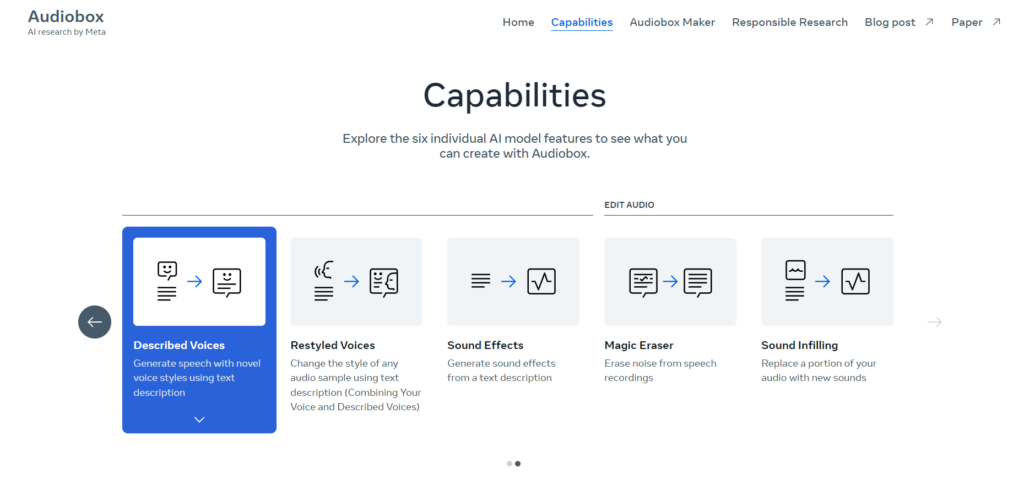
「Audiobox」のデモ版のUI 引用元:https://audiobox.metademolab.com/capabilities
次世代音声AIモデル「Audiobox」とは
今回発表されたAudioboxは「Voicebox」という前身モデルの後継として発表されました。Audioboxは言語による指示で、音声や効果音、環境音を含む幅広い音の生成が可能なAIモデルです。例えば「流れる川と鳥のさえずり」といったテキストプロンプトを入力すると、川の流れる音と鳥のさえずりのミックスされた環境音を生成することが可能になるそうです。
さらに、Audioboxは音声入力にも対応しています。入力した音声を用いてテキストを読ませたり、声を変えたり、環境音とミックスさせたりすることが可能になる模様です。
Audioboxの開発経緯
Metaは、映画やポッドキャストなどさまざまなメディアにおいて重要な役割を果たす音声が、専門的知識の欠如などにより、多くの人々にとって高い利用ハードルがあると考えているとのこと。こうした考えのもと、Audioboxは多くの人がオーディオコンテンツのクリエイターになるための障壁を下げることを目指して開発したといいます。
AIクリエイティブの可能性と問題点
テキストによる画像生成は、昨今非常に盛り上がりを見せている領域ですが、音声においてもこのような生成AI利用拡大の兆しが見えています。声や効果音はプロ仕様のものを用意することが非常に困難なものであるため、こうしたAI活用によって多くのクリエイターがより多くの素材を扱えるようになるかもしれません。
一方で画像生成AIで見られるような、悪用などの倫理的な問題が発生する可能性もあり、実用化という観点においては整備すべき点も多く存在しているといえるでしょう。
Voiceboxとは
Metaの「Voicebox」は、同社の「Audiobox」の前身のAI音声合成モデルで、実際の人間の声を模倣し、自然でリアルな音声を生成することが可能です。Voiceboxは、異なる言語や方言に対応し、様々な感情や口調を表現することが可能です。この技術は、バーチャルアシスタント、オーディオブック、ゲーム内のキャラクターの声など、多岐にわたる用途に活用されています。Voiceboxはその後、さらに進化した「Audiobox」としてアップデートし、音声合成の分野において重要な役割を担っています。
参照元:Audiobox: Generating audio from voice and natural language prompts






ほしい音を正確に言語化して言葉にするのって、結構むずかしいよね。