これまで本誌では、アリババグループの「EMO」や、OpenAIの新技術「Sora」など、様々な動画生成AIについて紹介してきました。今回また新たな動画生成AIとして、Googleの研究部門Google Researchから「VLOGGER」に関する論文が公開されました。このVLOGGERは、1枚の入力画像からテキストと音声主導で会話する人物の動画を生成するAI技術です。

引用元:VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
Googleの新技術「VLOGGER」とは
この新技術は、一つの人物画像をもとに、テキストと音声を掛け合わせることで、人が話している動画を作成することができます。本手法は、確率的な人間対3次元モーション拡散モデルと、テキスト対画像モデルを組み合わせ、時間的・空間的制御を補強する新しいアーキテクチャによって構成されています。
従来の研究とは異なり、VLOGGERは個々の人物のトレーニングを必要とせず、顔検出やトリミングに依存することなく、高品質で可変長のビデオを生成し、正確に合成することができるといいます。
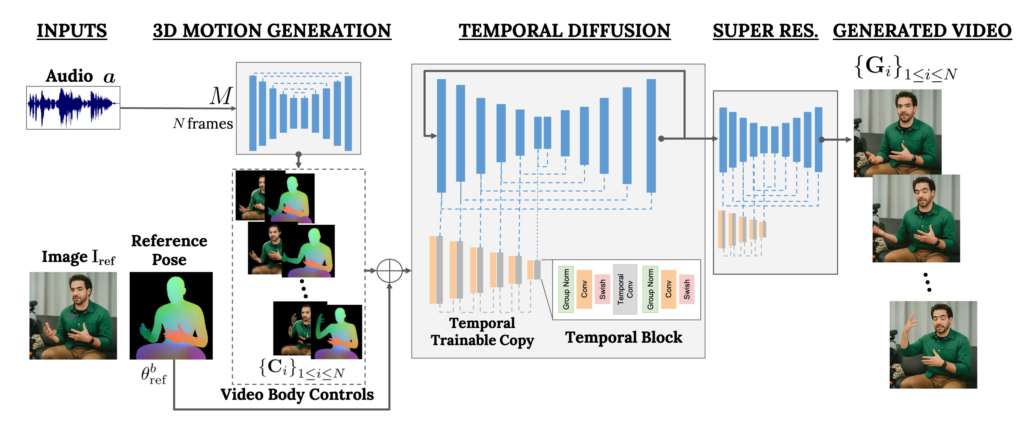
引用元:VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
ベンチマークを凌駕する性能の高さ
研究チームはVLOGGERを3つの異なるベンチマークで評価しており、その性能が画質、同一性保持、時間的一貫性において他の最先端技術を凌駕していることも示しています。従来よりも多様なデータセットMENTORの収集を通じて、VLOGGERの性能をさらに高めたということです。
撮影した動画の編集も可能
VLOGGERの用途の一つとして動画の編集が挙げられます。取り込んだ動画に対し、変化すべき画像部分を塗りつぶし、元の変化していないものと一致させます。その結果、被写体の表情や動きを変化させることができるといいます。

引用元:VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
動画生成AIの進化に伴い、ビデオや動画などのコンテンツ制作はもちろん、教育現場やエンターテインメント分野などにおける作業の効率化や創造性の拡大が期待されています。進化するAI技術が、どのように現場に導入されていくのか、今後も注視していきたいところです。
動画生成AIとは
動画生成AIは、人工知能(AI)を使用して、1つまたは複数の入力画像やテキストから、自動的に動画を生成する技術です。近年、GoogleやOpenAI、Metaなど様々な企業が動画生成AIの開発に注力しています。このAIは、顔や身体の動き、音声、背景などを考慮して、リアルな映像を生成し、様々な用途に活用されています。
引用/参照元:VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis

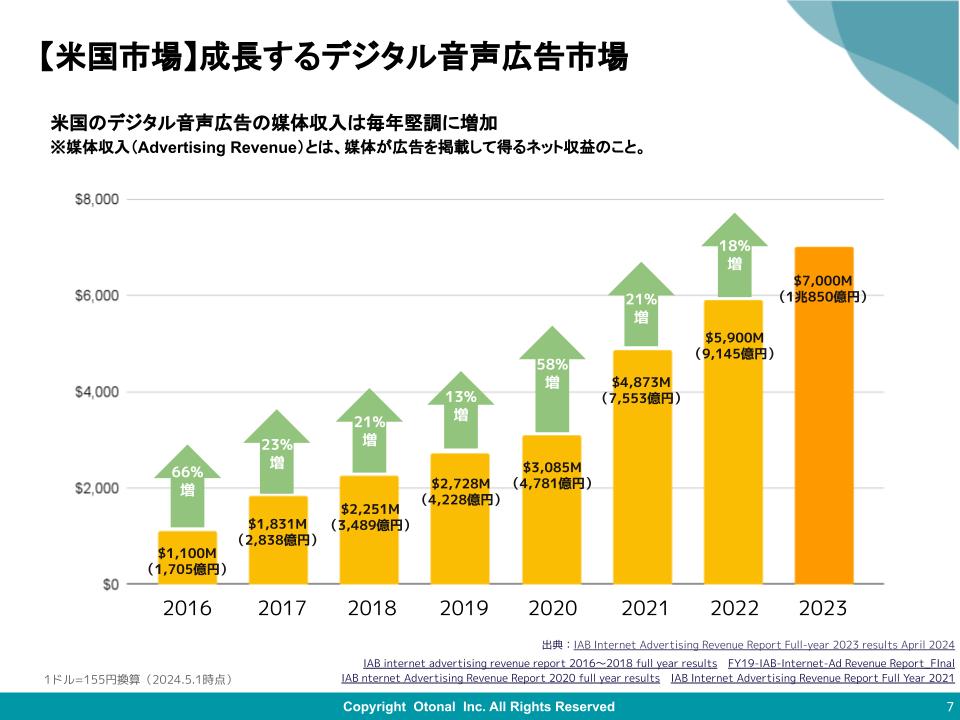
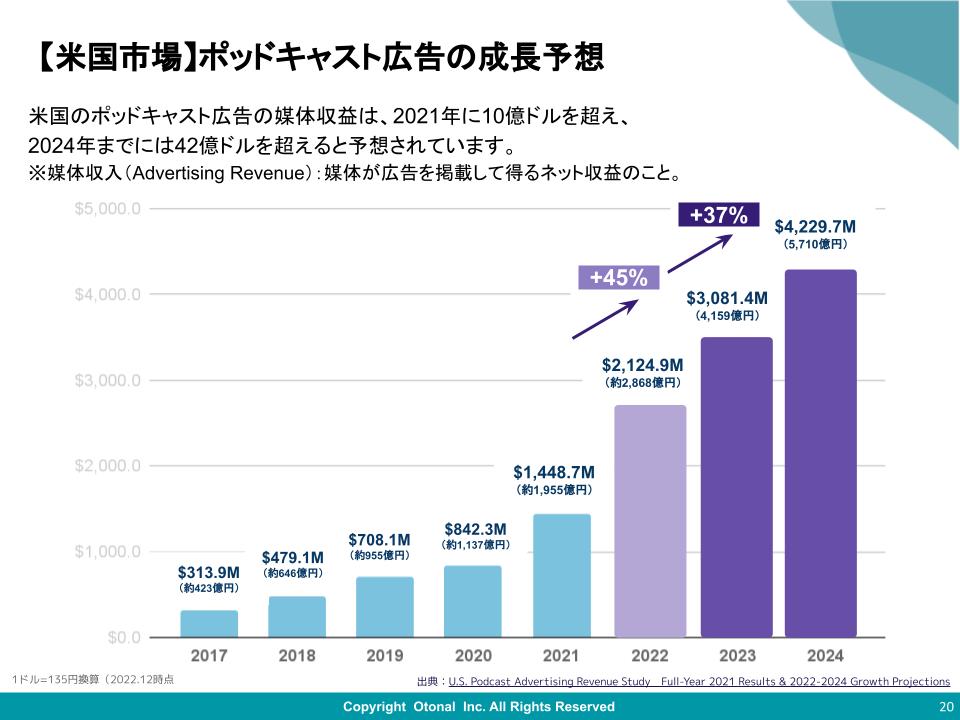




めちゃくちゃ自然だ。もう人間でも見分けられない領域に来ているのでは。