Googleが発表したVideoPoetが、最新の動画生成技術として注目を集めています。この大規模言語モデル(LLM)は、言語、コード、音声など、様々なモダリティにわたり高い学習能力を備えているため、キーワードを与えることによって動画生成が可能となるということです。

引用元:VideoPoet: A large language model for zero-shot video generation
VideoPoetの特徴と応用範囲
VideoPoetは単一のLLM内で多岐にわたるビデオ生成機能をシームレスに統合しています。これにより、通常のビデオ生成モデルはと異なり、テキストから動画、画像から動画、動画のスタイリング、動画の編集など、様々な動画生成タスクに柔軟に対応できます。
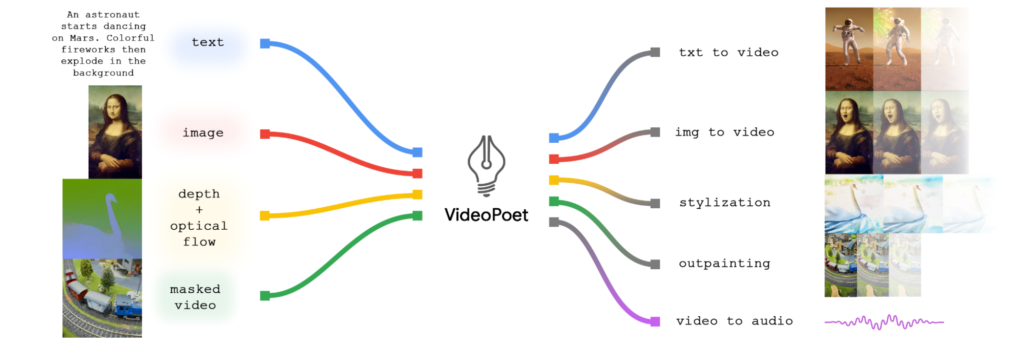
引用元:VideoPoet: A large language model for zero-shot video generation
VideoPoetの機能は動画生成だけではない
VideoPoetはビデオ生成においては、テキスト入力に基づいて動画を生成するだけでなく、その生成物を編集したり、インタラクティブに制御することが可能です。例えば、テキストから音声や画像への変換、動画の長さやスタイルの調整など、幅広くさまざまなことに応用できるということです。

VideoPoetの生成例を紹介
テキストから動画を作成
テキストをビデオに変換する場合、ビデオ出力の長さは調整することが可能で、テキストの内容に応じてさまざまなモーションやスタイルを適用できます。

“A Raccoon dancing in Times Square”
縦向き動画の短編コンテンツを生成
こちらの短編コンテンツの脚本はBardによって書かれているということです。動画の中では旅するアライグマの冒険がシーンごとに綴られ、それぞれの場面に合わせたプロンプトが付随しています。各プロンプトに基づいてVideoPoetが生成したビデオクリップが、見事に組み合わされて編集されており、感動的で楽しい短編ビデオとなっています。
これからの動画生成技術の展望
VideoPoetの登場により、LLMが動画生成分野において高い競争力を持つことが示されました。将来的には、テキストからオーディオへ、オーディオからビデオへといった「any-to-any」生成が可能となり、この技術がますます進化していくことが予想されます。
Videopoetの機能はまだ一般公開されておらず、試すことはできませんが、Webサイトで紹介されているデモではその精度の高い生成例を体験することができます。以前紹介した、Google DeepMindが最新AI音楽生成モデル「Lyria」然り、AIによる制作技術の飛躍は凄まじく、今後も注目を続けていきたいところです。
大規模言語モデル(LLM)とは
大規模言語モデル(LLM)は、巨大なデータセットで訓練され、自然言語処理タスクにおいて高度な表現力を持つ人工知能モデルのことを指します。テキスト生成、質問応答、文章理解など、広範な言語タスクに適用可能で、事前のタスク特定のトレーニングなしに様々な任務に対応できる特長があります。今回のVideoPoetもこのモデルを活用しており、さまざまなタスクにおいて高い競争力を持つことが実証されています。
参照/引用元:VideoPoet: A large language model for zero-shot video generation

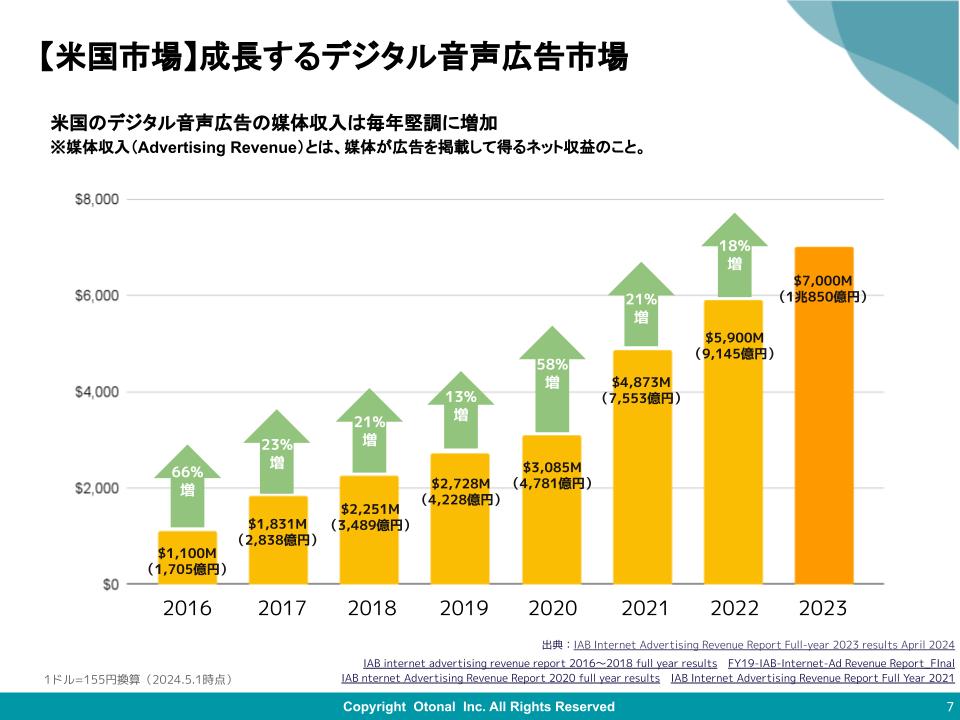
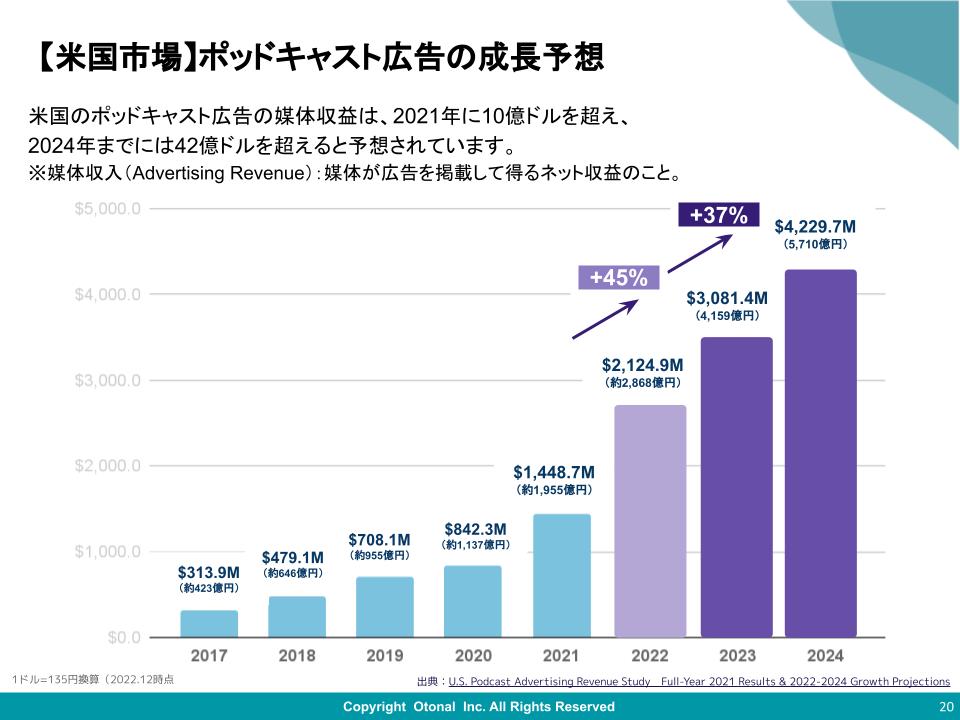




何を表現したいかっていうゼロイチの部分は、やっぱり人間が頭をひねる必要があるよね。